MLA-C01 Exam Dumps - AWS Certified Machine Learning Engineer - Associate
Searching for workable clues to ace the Amazon Web Services MLA-C01 Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s MLA-C01 PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
An ML engineer is building an ML model in Amazon SageMaker AI. The ML engineer needs to load historical data directly from Amazon S3, Amazon Athena, and Snowflake into SageMaker AI.
Which solution will meet this requirement?
A company wants to build an anomaly detection ML model. The model will use large-scale tabular data that is stored in an Amazon S3 bucket. The company does not have expertise in Python, Spark, or other languages for ML.
An ML engineer needs to transform and prepare the data for ML model training.
Which solution will meet these requirements?
A company ' s ML engineer is creating a classification model. The ML engineer explores the dataset and notices a column named day_of_week. The column contains the following values: Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday.
Which technique should the ML engineer use to convert this column’s data to binary values?
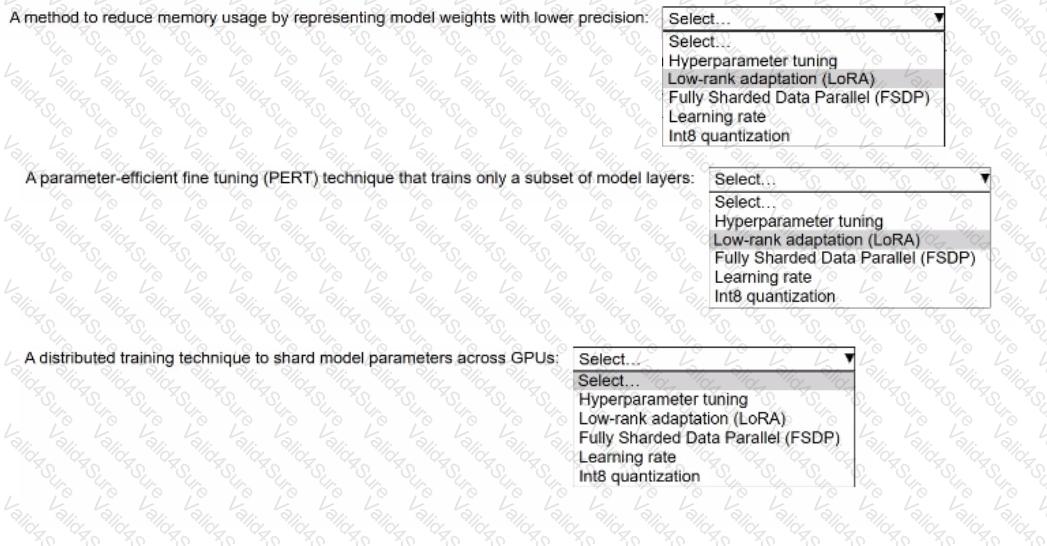
An ML engineer is using Amazon SageMaker JumpStart to fine-tune a Llama 3.2 model for text generation. The ML engineer is using an instruction-based fine-tuning method. The model uses 70 billion parameters.
Select the correct fine-tuning term from the following list to match each description. Select each term one time or not at all. (Select THREE.)
• Hyperparameter tuning
• Low-rank adaptation (LoRA)
• Fully Sharded Data Parallel (FSDP)
• Learning rate
• Int8 quantization
A company uses Amazon SageMaker Studio to develop an ML model. The company has a single SageMaker Studio domain. An ML engineer needs to implement a solution that provides an automated alert when SageMaker compute costs reach a specific threshold.
Which solution will meet these requirements?