MLA-C01 Exam Dumps - AWS Certified Machine Learning Engineer - Associate
Searching for workable clues to ace the Amazon Web Services MLA-C01 Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s MLA-C01 PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
A company is using Amazon SageMaker AI to build an ML model to predict customer behavior. The company needs to explain the bias in the model to an auditor. The explanation must focus on demographic data of the customers.
Which solution will meet these requirements?
A company wants to use large language models (LLMs) supported by Amazon Bedrock to develop a chat interface for internal technical documentation.
The documentation consists of dozens of text files totaling several megabytes and is updated frequently.
Which solution will meet these requirements MOST cost-effectively?
A company is using an AWS Lambda function to monitor the metrics from an ML model. An ML engineer needs to implement a solution to send an email message when the metrics breach a threshold.
Which solution will meet this requirement?
A company wants to use Amazon SageMaker AI to host an ML model that runs on CPU for real-time predictions. The model has intermittent traffic during business hours and periods of no traffic after business hours.
Which hosting option will serve inference requests in the MOST cost-effective manner?
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records every second.
The company needs to implement a scalable solution on AWS to identify anomalous data points.
Which solution will meet these requirements with the LEAST operational overhead?
A company regularly receives new training data from the vendor of an ML model. The vendor delivers cleaned and prepared data to the company ' s Amazon S3 bucket every 3-4 days.
The company has an Amazon SageMaker pipeline to retrain the model. An ML engineer needs to implement a solution to run the pipeline when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
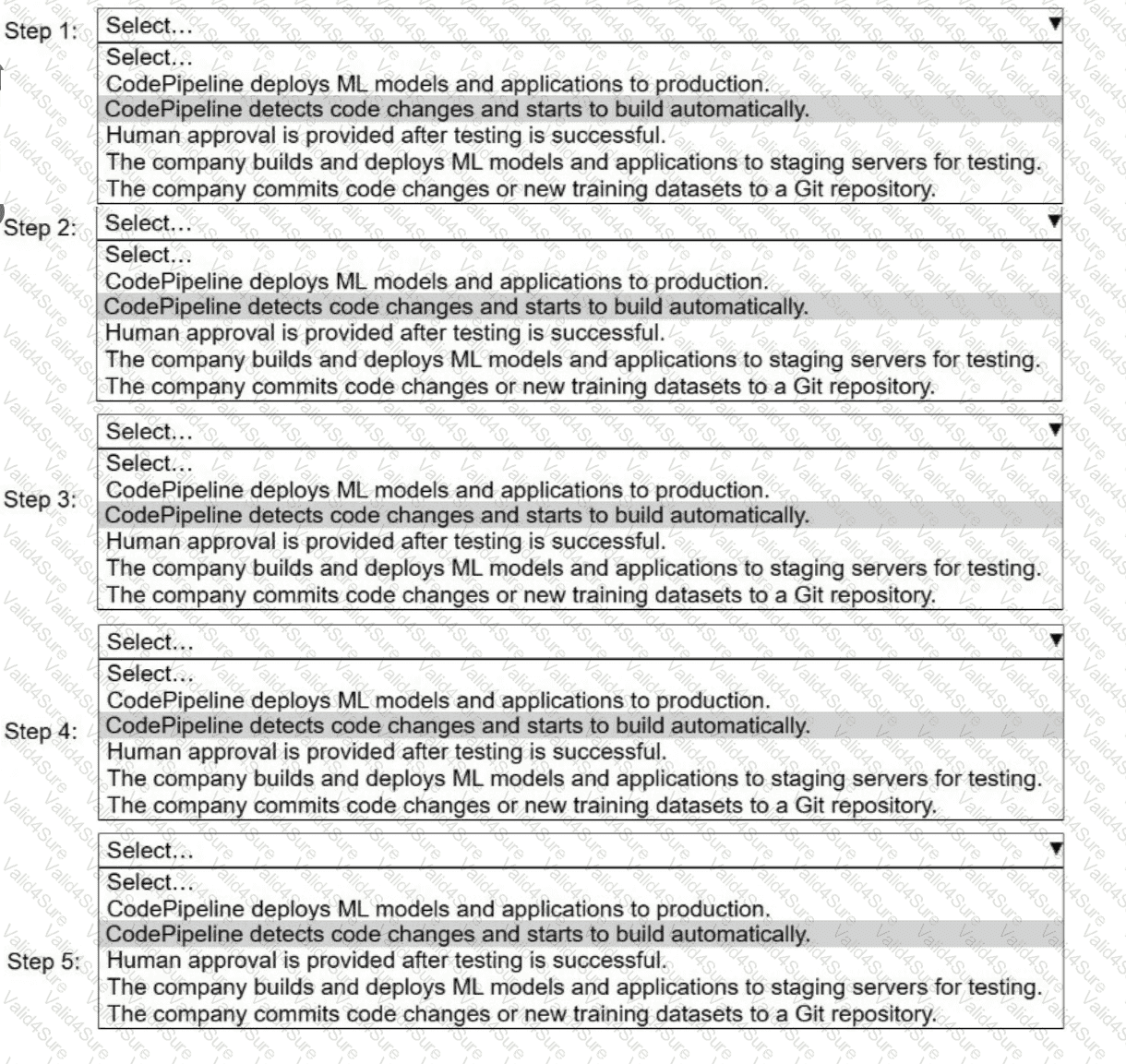
A company uses AWS CodePipeline to orchestrate a continuous integration and continuous delivery (CI/CD) pipeline for ML models and applications.
Select and order the steps from the following list to describe a CI/CD process for a successful deployment. Select each step one time. (Select and order FIVE.)
. CodePipeline deploys ML models and applications to production.
· CodePipeline detects code changes and starts to build automatically.
. Human approval is provided after testing is successful.
. The company builds and deploys ML models and applications to staging servers for testing.
. The company commits code changes or new training datasets to a Git repository.
A travel company has trained hundreds of geographic data models to answer customer questions by using Amazon SageMaker AI. Each model uses its own inferencing endpoint, which has become an operational challenge for the company.
The company wants to consolidate the models ' inferencing endpoints to reduce operational overhead.
Which solution will meet these requirements?