MLA-C01 Exam Dumps - AWS Certified Machine Learning Engineer - Associate
Searching for workable clues to ace the Amazon Web Services MLA-C01 Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s MLA-C01 PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
An ML engineer decides to use Amazon SageMaker AI automated model tuning (AMT) for hyperparameter optimization (HPO). The ML engineer requires a tuning strategy that uses regression to slowly and sequentially select the next set of hyperparameters based on previous runs. The strategy must work across small hyperparameter ranges.
Which solution will meet these requirements?
A company uses an Amazon SageMaker AI model for real-time inference with auto scaling enabled. During peak usage, new instances launch before existing instances are fully ready, causing inefficiencies and delays.
Which solution will optimize the scaling process without affecting response times?
An ML engineer wants to run a training job on Amazon SageMaker AI by using multiple GPUs. The training dataset is stored in Apache Parquet format.
The Parquet files are too large to fit into the memory of the SageMaker AI training instances.
Which solution will fix the memory problem?
A streaming media company uses a churn risk model to assess the churn risk of its premium tier customers. Each month, the company runs an aggregation job on individual customers’ streaming data and uploads the user engagement features to an Amazon S3 bucket. The company manually re-trains the churn risk model with the user engagement data.
The current process requires manual intervention and is time-consuming. The company needs a solution that automatically re-trains the churn prediction model with the most recent data.
Which solution will meet these requirements with the SHORTEST delay?
A company has AWS Glue data processing jobs that are orchestrated by an AWS Glue workflow. The AWS Glue jobs can run on a schedule or can be launched manually.
The company is developing pipelines in Amazon SageMaker Pipelines for ML model development. The pipelines will use the output of the AWS Glue jobs during the data processing phase of model development. An ML engineer needs to implement a solution that integrates the AWS Glue jobs with the pipelines.
Which solution will meet these requirements with the LEAST operational overhead?
A company wants to host an ML model on Amazon SageMaker. An ML engineer is configuring a continuous integration and continuous delivery (Cl/CD) pipeline in AWS CodePipeline to deploy the model. The pipeline must run automatically when new training data for the model is uploaded to an Amazon S3 bucket.
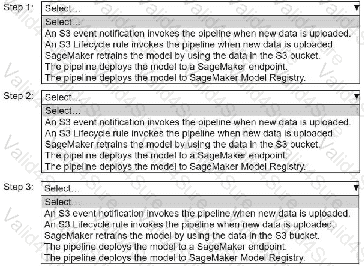
Select and order the pipeline ' s correct steps from the following list. Each step should be selected one time or not at all. (Select and order three.)
• An S3 event notification invokes the pipeline when new data is uploaded.
• S3 Lifecycle rule invokes the pipeline when new data is uploaded.
• SageMaker retrains the model by using the data in the S3 bucket.
• The pipeline deploys the model to a SageMaker endpoint.
• The pipeline deploys the model to SageMaker Model Registry.

A company is planning to use Amazon SageMaker to make classification ratings that are based on images. The company has 6 ТВ of training data that is stored on an Amazon FSx for NetApp ONTAP system virtual machine (SVM). The SVM is in the same VPC as SageMaker.
An ML engineer must make the training data accessible for ML models that are in the SageMaker environment.
Which solution will meet these requirements?
An ML engineer is using a training job to fine-tune a deep learning model in Amazon SageMaker Studio. The ML engineer previously used the same pre-trained model with a similar
dataset. The ML engineer expects vanishing gradient, underutilized GPU, and overfitting problems.
The ML engineer needs to implement a solution to detect these issues and to react in predefined ways when the issues occur. The solution also must provide comprehensive real-time metrics during the training.
Which solution will meet these requirements with the LEAST operational overhead?