MLA-C01 Exam Dumps - AWS Certified Machine Learning Engineer - Associate
Searching for workable clues to ace the Amazon Web Services MLA-C01 Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s MLA-C01 PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
A company is developing ML models by using PyTorch and TensorFlow estimators with Amazon SageMaker AI. An ML engineer configures the SageMaker AI estimator and now needs to initiate a training job that uses a training dataset.
Which SageMaker AI SDK method can initiate the training job?
A company has an ML model in Amazon SageMaker AI. An ML engineer needs to implement a monitoring solution to automatically detect changes in the input data distribution of model features.
Which solution will meet this requirement with the LEAST operational overhead?
A company runs an Amazon SageMaker AI domain in a public subnet of a newly created VPC. The network is configured properly, and ML engineers can access the SageMaker AI domain.
Recently, the company discovered suspicious traffic to the domain from a specific IP address. The company needs to block traffic from the specific IP address.
Which update to the network configuration will meet this requirement?
Case Study
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a
central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company must implement a manual approval-based workflow to ensure that only approved models can be deployed to production endpoints.
Which solution will meet this requirement?
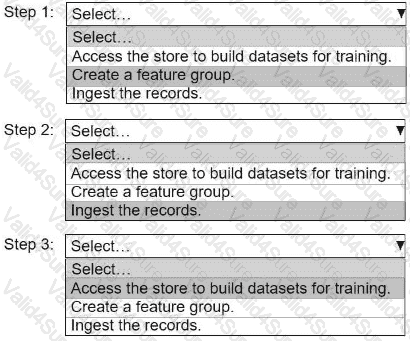
An ML engineer needs to use Amazon SageMaker Feature Store to create and manage features to train a model.
Select and order the steps from the following list to create and use the features in Feature Store. Each step should be selected one time. (Select and order three.)
• Access the store to build datasets for training.
• Create a feature group.
• Ingest the records.
An ML company wants to monitor and analyze the API calls that its AWS resources make. The company has created an AWS CloudTrail log file that logs to an Amazon S3 bucket. The company has also created an organization in AWS Organizations to manage permissions across accounts.
The company needs to enable log file validation to ensure the integrity of its log files.
Which solution will meet these requirements?
A company needs to host a custom ML model to perform forecast analysis. The forecast analysis will occur with predictable and sustained load during the same 2-hour period every day.
Multiple invocations during the analysis period will require quick responses. The company needs AWS to manage the underlying infrastructure and any auto scaling activities.
Which solution will meet these requirements?
A company is using Amazon SageMaker AI to develop a credit risk assessment model. During model validation, the company finds that the model achieves 82% accuracy on the validation data. However, the model achieved 99% accuracy on the training data. The company needs to address the model accuracy issue before deployment.
Which solution will meet this requirement?