Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Exam Dumps - Databricks Certified Associate Developer for Apache Spark 3.5 – Python
Searching for workable clues to ace the Databricks Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
A data engineer replaces the exact percentile() function with approx_percentile() to improve performance, but the results are drifting too far from expected values.
Which change should be made to solve the issue?
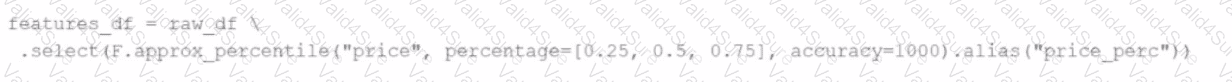
16 of 55.
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior? (Choose 2 answers)
A data analyst wants to add a column date derived from a timestamp column.
Options:
A data engineer is working on the DataFrame:
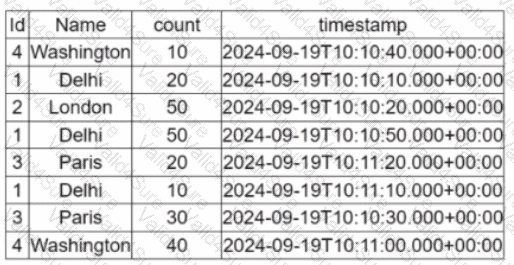
(Referring to the table image: it has columns Id, Name, count, and timestamp.)
Which code fragment should the engineer use to extract the unique values in the Name column into an alphabetically ordered list?
47 of 55.
A data engineer has written the following code to join two DataFrames df1 and df2:
df1 = spark.read.csv("sales_data.csv")
df2 = spark.read.csv("product_data.csv")
df_joined = df1.join(df2, df1.product_id == df2.product_id)
The DataFrame df1 contains ~10 GB of sales data, and df2 contains ~8 MB of product data.
Which join strategy will Spark use?