DP-100 Exam Dumps - Designing and Implementing a Data Science Solution on Azure
Searching for workable clues to ace the Microsoft DP-100 Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s DP-100 PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
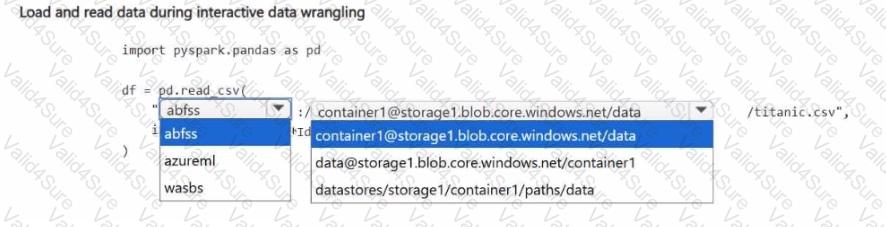
You manage an Azure Machine Learning workspace. The titanic.csv file is available in an Azure Blob Storage account named storage1. The container name is container"!. The folder name is data.
You perform interactive data wrangling by using a serverless Spark compute.
You need to load the data from Blob Storage into a Pandas dataframe.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You use the Azure Machine Learning SDK to run a training experiment that trains a classification model and calculates its accuracy metric.
The model will be retrained each month as new data is available.
You must register the model for use in a batch inference pipeline.
You need to register the model and ensure that the models created by subsequent retraining experiments are registered only if their accuracy is higher than the currently registered model.
What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these
questions will not appear in the review screen.
You are creating a model to predict the price of a student’s artwork depending on the following variables: the student’s length of education, degree type, and art form.
You start by creating a linear regression model.
You need to evaluate the linear regression model.
Solution: Use the following metrics: Relative Squared Error, Coefficient of Determination, Accuracy, Precision, Recall, F1 score, and AUC.
Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:

The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
run.log_list('Label Values', label_vals)
Does the solution meet the goal?
You are tuning a hyperparameter for an algorithm. The following table shows a data set with different hyperparameter, training error, and validation errors.
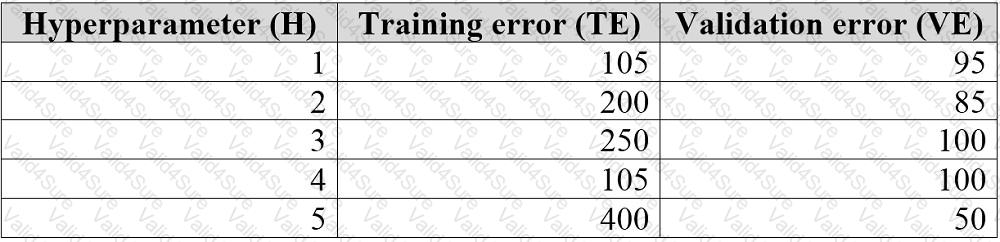
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.

You use Azure Machine Learning studio to analyze an mltable data asset containing a decimal column named column1. You need to verify that the column1 values are normally distributed.
Which statistic should you use?
You have an Azure Machine Learning workspace that includes an AmICompute cluster and a batch endpoint. You clone a repository that contains an MLflow model to your local computer. You need to ensure that you can deploy the model to the batch endpoint.
Solution: Create a data asset in the workspace.
Does the solution meet the goal?
You run a script as an experiment in Azure Machine Learning.
You have a Run object named run that references the experiment run. You must review the log files that were generated during the experiment run.
You need to download the log files to a local folder for review.
Which two code segments can you run to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.