Databricks-Certified-Professional-Data-Scientist Exam Dumps - Databricks Certified Professional Data Scientist Exam
Searching for workable clues to ace the Databricks Databricks-Certified-Professional-Data-Scientist Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s Databricks-Certified-Professional-Data-Scientist PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
You are working on a email spam filtering assignment, while working on this you find there is new word e.g. HadoopExam comes in email, and in your solutions you never come across this word before, hence probability of this words is coming in either email could be zero. So which of the following algorithm can help you to avoid zero probability?
What is one modeling or descriptive statistical function in MADlib that is typically not provided in a standard relational database?
You are using one approach for the classification where to teach the agent not by giving explicit categorizations, but by using some sort of reward system to indicate success, where agents might be rewarded for doing certain actions and punished for doing others. Which kind of this learning
Suppose a man told you he had a nice conversation with someone on the train. Not knowing anything about this conversation, the probability that he was speaking to a woman is 50% (assuming the train had an equal number of men and women and the speaker was as likely to strike up a conversation with a man as with a woman). Now suppose he also told you that his conversational partner had long hair. It is now more
likely he was speaking to a woman, since women are more likely to have long hair than men.____________
can be used to calculate the probability that the person was a woman.
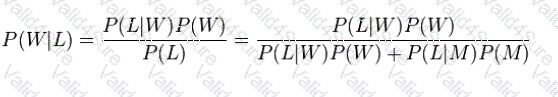 Text
Description automatically generated with low confidence
Text
Description automatically generated with low confidence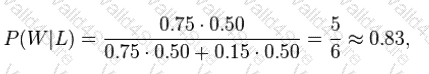 A picture containing table
Description automatically generated
A picture containing table
Description automatically generated