DP-700 Exam Dumps - Implementing Data Engineering Solutions Using Microsoft Fabric
Searching for workable clues to ace the Microsoft DP-700 Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s DP-700 PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
You need to recommend a solution to resolve the MAR1 connectivity issues. The solution must minimize development effort. What should you recommend?
You need to recommend a solution for handling old files. The solution must meet the technical requirements. What should you include in the recommendation?
DRAG DROP
You have a Fabric eventhouse that contains a KQL database. The database contains a table named TaxiData. The following is a sample of the data in TaxiData.
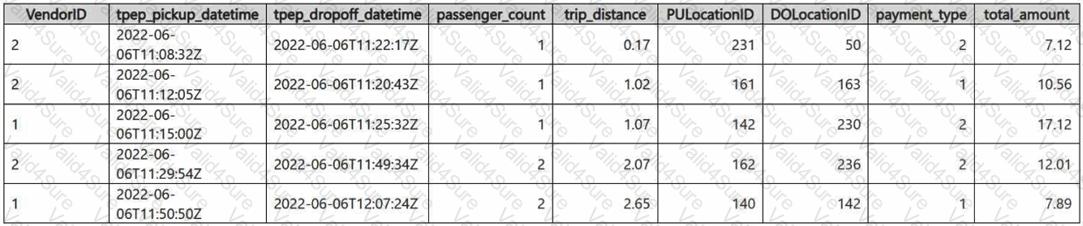
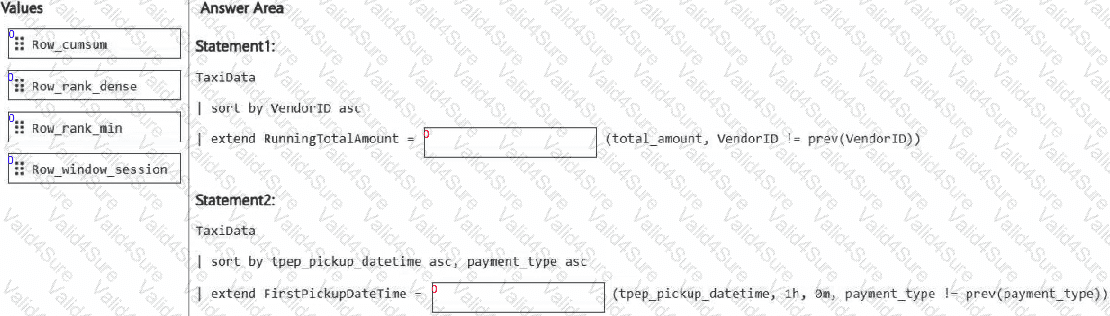
You need to build two KQL queries. The solution must meet the following requirements:
One of the queries must partition RunningTotalAmount by VendorID.
The other query must create a column named FirstPickupDateTime that shows the first value of each hour from tpep_pickup_datetime partitioned by payment_type.
How should you complete each query? To answer, drag the appropriate values the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.



You have a Fabric workspace that contains a data pipeline named Pipeline1 and a notebook named Notebook1. Pipeline1 contains an activity that is used to run Notebook1. Pipeline! is scheduled to run every 10 minutes.
You receive an alert that Pipeline! failed during the notebook execution activity.
You need to identify in which cell the failure occurred.
What should you do from Monitor in the Fabric admin center?
You have a Fabric workspace named Workspace1 that contains a warehouse named Warehouse1.
You plan to deploy Warehouse1 to a new workspace named Workspace2.
As part of the deployment process, you need to verify whether Warehouse1 contains invalid references. The solution must minimize development effort.
What should you use?
You have a Fabric workspace that contains an eventstream named Eventstream1. Eventstream1 processes data from a thermal sensor by using event stream processing, and then stores the data in a lakehouse.
You need to modify Eventstream1 to include the standard deviation of the temperature.
Which transform operator should you include in the Eventstream1 logic?
You have a Fabric workspace that contains a warehouse named Warehouse1.
You have an on-premises Microsoft SQL Server database named Database1 that is accessed by using an on-premises data gateway.
You need to copy data from Database1 to Warehouse1.
Which item should you use?
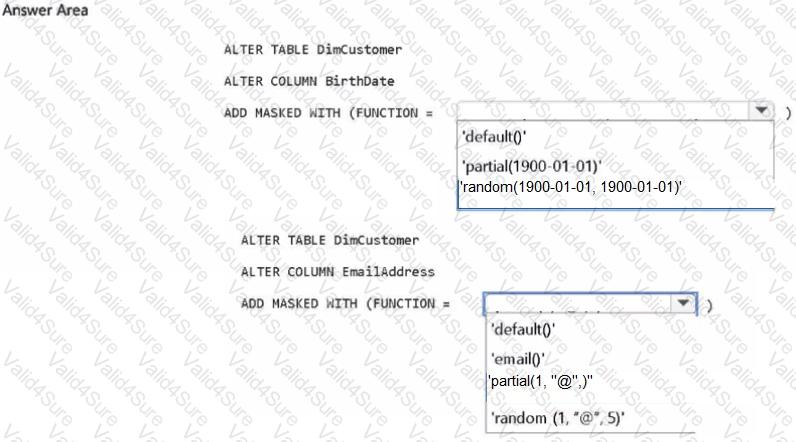
You have a Fabric workspace that contains a warehouse named Warehouse1 Warehousel contains a table named DimCustomers. DimCustomers contains the following columns:
• CustomerName
• CustomerlD
• Birth Date
• Email
You need to configure security to meet the following requirements:
• Birth Date in DimCustomer must be masked and display 1960-01-01
• Email in DimCustomer must be masked and display only the first leading character and the last five characters.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.