DP-203 Exam Dumps - Data Engineering on Microsoft Azure
Searching for workable clues to ace the Microsoft DP-203 Exam? You’re on the right place! ExamCert has realistic, trusted and authentic exam prep tools to help you achieve your desired credential. ExamCert’s DP-203 PDF Study Guide, Testing Engine and Exam Dumps follow a reliable exam preparation strategy, providing you the most relevant and updated study material that is crafted in an easy to learn format of questions and answers. ExamCert’s study tools aim at simplifying all complex and confusing concepts of the exam and introduce you to the real exam scenario and practice it with the help of its testing engine and real exam dumps
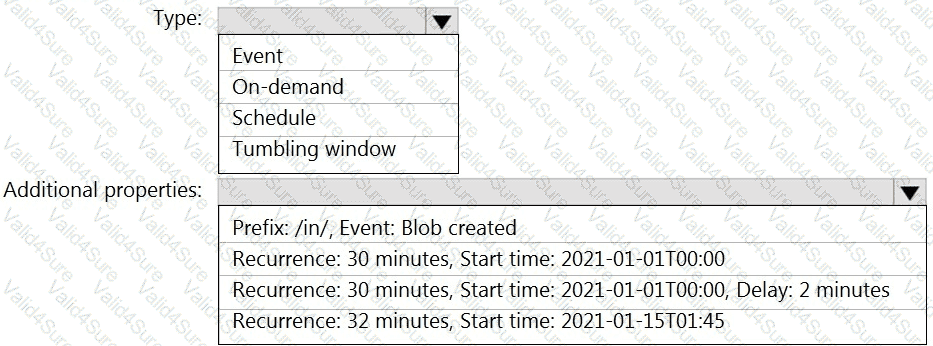
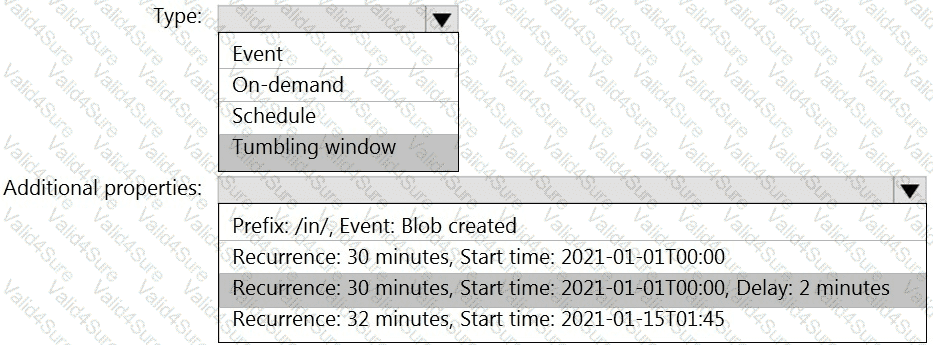
You build an Azure Data Factory pipeline to move data from an Azure Data Lake Storage Gen2 container to a database in an Azure Synapse Analytics dedicated SQL pool.
Data in the container is stored in the following folder structure.
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
The earliest folder is /in/2021/01/01/00/00. The latest folder is /in/2021/01/15/01/45.
You need to configure a pipeline trigger to meet the following requirements:
Existing data must be loaded.
Data must be loaded every 30 minutes.
Late-arriving data of up to two minutes must he included in the load for the time at which the data should have arrived.
How should you configure the pipeline trigger? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have a table named SalesFact in an enterprise data warehouse in Azure Synapse Analytics. SalesFact contains sales data from the past 36 months and has the following characteristics:
Is partitioned by month
Contains one billion rows
Has clustered columnstore indexes
At the beginning of each month, you need to remove data from SalesFact that is older than 36 months as quickly as possible.
Which three actions should you perform in sequence in a stored procedure? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


You have an Azure Synapse Analytics workspace.
You plan to deploy a lake database by using a database template in Azure Synapse.
Which two elements ate included in the template? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You schedule an Azure Databricks job that executes an R notebook, and then inserts the data into the data warehouse.
Does this meet the goal?
You have an Azure subscription that contains the resources shown in the following table.

You need to read the files in storage1 by using ad-hoc queries and the openrowset function. The solution must ensure that each rowset contains a single JSON record.
To what should you set the format option of the openrowset function?